
1. AI 워크로드에 대한 컨테이너 사용
AI 워크로드와 컨테이너: GPU 가상화의 필요성
최근, AI가 대두되면서, 더욱 복잡하고, 대용량 데이터를 처리하는 모델을 다루면서, 이러한 워크로드는 고성능 GPU 인프라를 요구한다.
특히 병렬 연산에 특화된 GPU는 딥러닝 학습 속도를 크게 향상한다. 과거에는 베어메탈 환경에 직접 GPU 드라이버와 프레임워크(CUDA, cuDNN 등)를 설치해 사용하는 방식이 일반적이었다.
하지만 이 방식은 다음과 같은 문제를 안고 있었다:
• 환경 구성이 복잡하고 프레임워크마다 버전 호환성이 까다롭다.
• GPU 리소스가 특정 사용자에 고정되면서 전체 활용률이 낮아진다.
• 대규모 분산 학습 환경으로의 확장이 어렵다.
컨테이너 기술 도입 이후 개선된 점과 한계
컨테이너는 Linux 커널의 cgroups, namespaces 기능을 기반으로 리소스를 논리적으로 격리한다.
이를 통해 CPU, 메모리 등 일반 리소스는 효과적으로 컨트롤할 수 있게 되었지만,
GPU는 구조상 몇 가지 제약이 존재한다.
• 초기 GPU는 물리적으로 분할할 수 없어, 한 컨테이너가 GPU 전체를 독점해야 했다.
• GPU 접근은 복잡한 드라이버 및 커널 모듈 의존성이 크다.
• /dev/nvidia* 장치 파일에 대한 접근 제어도 까다롭다.
이러한 한계를 해결하기 위해 등장한 것이 GPU 가상화 기술이다.
GPU 가상화 기술
MIG(Multi-Instance GPU) - NVIDIA A100 이상
MIG는 NVIDIA A100부터 도입된 하드웨어 기반 가상화 기능으로, 하나의 GPU를 여러 인스턴스로 분할하여 독립적으로 사용할 수 있게 해 준다.
• 각 인스턴스는 메모리, 캐시, 컴퓨팅 코어가 완전히 격리됨
• 서로 다른 워크로드를 동시에 실행할 수 있고, 자원 프로비저닝도 유연함
• 예: A100 40GB → 10GB 인스턴스 4개 + 5GB 인스턴스 2개 구성 가능
특히 GPU를 공유하는 환경에서 고정된 자원 분할이 가능하다는 점에서, 클라우드 환경이나 멀티 테넌트 환경에서 유용하게 사용된다.
vGPU(Virtual GPU) - 하이퍼바이저 기반
vGPU는 하이퍼바이저 기반 가상화 방식으로, CPU 가상화 방식과 유사하게 동작한다.
• GPU 메모리는 논리적으로 분할되고, 컴퓨팅 자원은 시간 단위로 공유된다
• VM 또는 컨테이너 단위로 할당되며, 가상 머신 간 자원 격리가 가능하다
• NVIDIA GRID 소프트웨어와 함께 구성되며, 주로 VDI나 대규모 가상 환경에 활용된다
단점으로는 메모리 접근이나 스케줄링 시 오버헤드가 존재할 수 있으며, 사용 환경에 따라 성능 차이가 발생할 수 있다.
컨테이너 환경에서의 GPU 리소스 사용 진화
1단계: 직접 장치 마운트 (2016–2018)
초기에는 GPU 장치 파일(/dev/nvidia*)을 컨테이너에 직접 마운트하고, CUDA 라이브러리 경로를 수동으로 지정하는 방식으로 GPU를 활용했다.
docker run --device=/dev/nvidia0:/dev/nvidia0 \
--device=/dev/nvidiactl:/dev/nvidiactl \
-v /usr/local/cuda:/usr/local/cuda \
tensorflow/tensorflow:latest-gpu
문제점:
- 장치 파일, 라이브러리 수동 지정 필요
- 호스트와 컨테이너 간 라이브러리 충돌 가능
- GPU 공유 불가
- Kubernetes와 같은 오케스트레이터에서 사용 어려움
2단계: NVIDIA Container Runtime 도입 (2018–2020)
NVIDIA는 GPU 장치 자동 마운트, 드라이버 주입, CUDA 호환성 체크 등을 자동화하는 런타임을 발표했다.
개선점
• --gpus 플래그 하나로 GPU 자동 인식
• 호스트 드라이버와 호환되는 환경 자동 구성
• GPU 컨테이너 이식성 향상
# Docker 19.03 이후
docker run --gpus '"device=0,1"' nvidia/cuda:11.0-base nvidia-smi
3단계: Kubernetes Device Plugin 등장 (2020–현재)
Kubernetes는 Device Plugin 메커니즘을 도입해, GPU를 포함한 특수 장치를 스케줄링할 수 있게 했다. NVIDIA도 공식 Device Plugin을 제공한다.
resources:
limits:
nvidia.com/gpu: 2
장점
• 선언적 GPU 요청
• 클러스터 차원의 GPU 리소스 스케줄링
• GPU 자동 할당 및 격리
• 멀티 테넌트 환경에서 공정한 자원 분배 가능
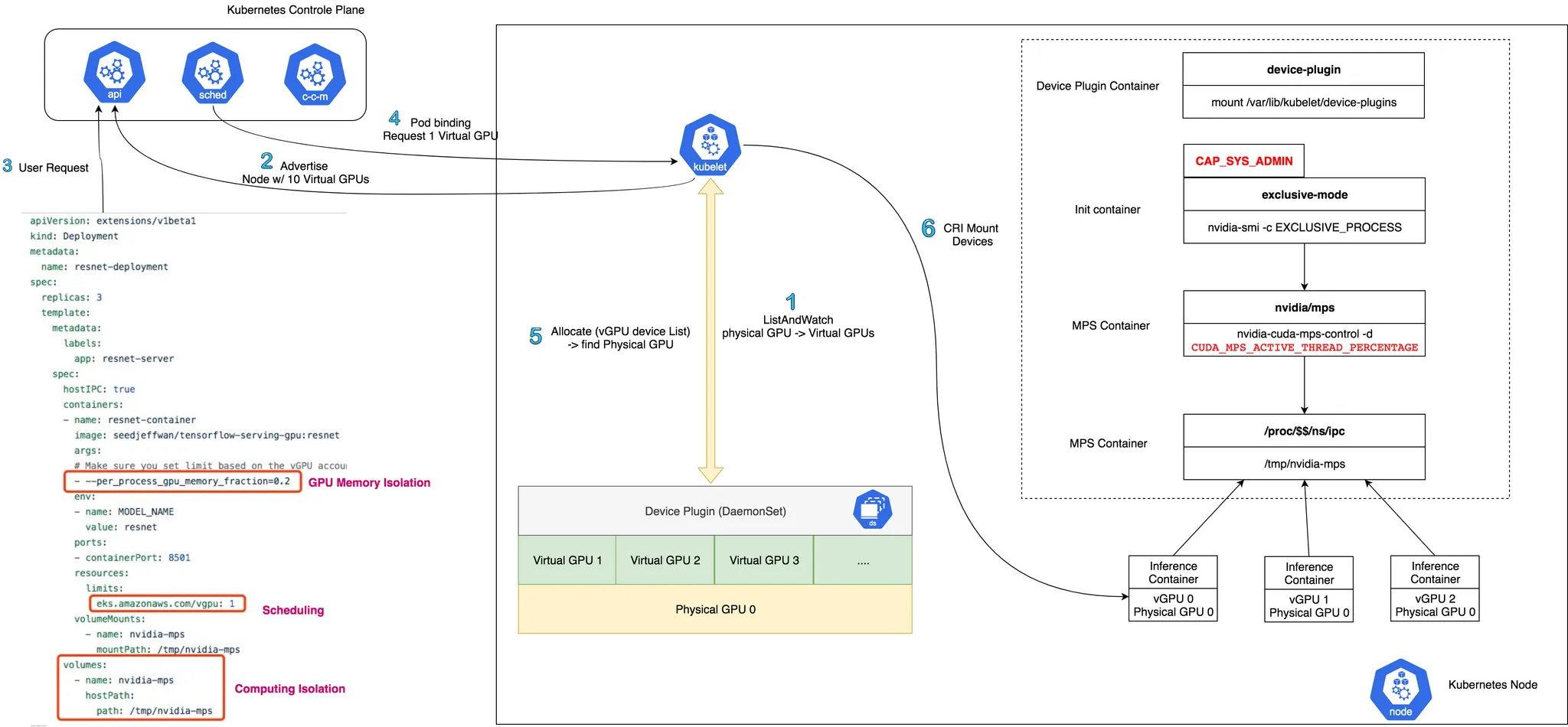
컨테이너 환경에서도 이제 GPU를 유연하게 나누고, 자동으로 할당하는 것이 가능해졌으며, GPU 가상화(MIG, vGPU)는 GPU 자원을 나누어 쓰기 위한 핵심 기술이다. Kubernetes + NVIDIA Device Plugin 조합은 AI 인프라에서 사실상 표준이 되었다.
실습 : GPU Time-slicing on Amazon EKS
AI 워크로드 실습을 위해서는 EC2 Quota(GPU)가 확보되어야 실습 가능, 요청일이 5일이 지났지만, 쿼터가 증설되지 않아, 추후 실습 예정(GPU 수급 이슈 문제로 인해 지연되는 것 같음)

2. 멀티 GPU 활용을 위한 AI/ML 인프라 with EKS
대규모 모델의 등장과 단일 GPU의 한계
최근 몇 년 사이 인공지능(AI) 모델의 규모는 상상을 초월할 정도로 커지고 있다. GPT와 같은 모델 등은수천억 개 이상의 파라미터로 구성되어 있어, 단일 GPU로는 더 이상 학습이 불가능한 시대가 되었다. 이로 인해 멀티 GPU, 멀티 노드 기반의 분산 학습(distributed training)은 필수가 되었다.
하지만 GPU를 여러 대 사용하는 것만으로는 문제가 해결되지 않는다. GPU 간 통신 효율이 전체 학습 속도에 큰 영향을 미치기 때문이다.
분산 학습에서 가장 큰 병목: GPU 간 네트워크 통신
멀티 GPU 또는 멀티 노드 환경에서는 학습 중에 각 노드가 그래디언트(gradient)를 서로 교환해야 한다. 문제는 이 네트워크 통신이 전체 학습 시간의 최대 70%까지 차지할 수 있어, 실제로 GPU 사용률이 60,70%까지 떨어지게 된다.
이러한 통신 병목을 줄이기 위해 NVIDIA는 NCCL(NVIDIA Collective Communications Library)을 개발했다.
NCCL은 다음과 같은 특징을 갖는다.
• GPU 간 집합 통신(AllReduce, Broadcast 등)을 최적화
• 다양한 연결 토폴로지(PCIe, NVLink, NVSwitch)를 자동 인식
• PyTorch, TensorFlow 등에 통합되어 별도 설정 없이 사용 가능
하지만 NCCL(소프트웨어)만으로는 해결할 수 없는 한계도 있다. 예를 들어 노드 간 통신은 여전히 네트워크 인프라의 물리적 한계에 종속되어 있기 때문이다.
AWS EFA: 분산 학습을 위한 고성능 네트워크 인터페이스
이 문제를 해결하기 위해 AWS는 EFA(Elastic Fabric Adapter)라는 고성능 네트워크 인터페이스를 제공한다.
EFA는 다음과 같은 기술을 바탕으로 GPU 간 통신 병목을 줄인다.
OS 바이패스 기술
기존 네트워크 스택에서는 커널을 거쳐야 했지만, EFA는 운영체제 커널을 우회해 사용자 공간에서 직접 네트워크 어댑터와 통신할 수 있게 한다.
• 시스템 콜 오버헤드 제거
• 커널 컨텍스트 스위칭 제거
• 인터럽트 처리 최소화
RDMA (Remote Direct Memory Access)
RDMA는 CPU 개입 없이 원격 메모리에 직접 접근할 수 있게 해 준다.
• 제로 카피(Zero-copy) 데이터 전송
• 빠른 전송을 위한 Direct Memory Access(DMA) 활용
• 고성능 컴퓨팅(HPC)에서도 이미 입증된 기술
NCCL과의 통합 최적화
EFA는 NCCL과의 긴밀한 통합을 통해
• GPU 직접 통신을 자동 최적화
• 토폴로지 인식 알고리즘으로 트래픽 분산
• 설정 없이도 학습 성능 향상
단순히 GPU 수를 늘리는 것만으로는 분산 학습이 최적화되지 않고, 통신 효율을 고려한 인프라 설계가 중요하며, NCCL과 EFA는 이를 위한 핵심 도구이다. Amazon EKS는 이러한 요소를 컨테이너 기반으로 유연하게 조합할 수 있는 플랫폼을 제공하며, 대규모 AI 워크로드의 학습 효율을 높이는 기반이 될 수 된다.
실습 : Multi GPU 사용
AI 워크로드 실습을 위해서는 EC2 Quota(GPU)가 확보되어야 실습 가능, 요청일이 5일이 지났지만, 쿼터가 증설되지 않아, 추후 실습 예정(GPU 수급 이슈 문제로 인해 지연되는 것 같음)

3. GenAI with Inferentia & FSx Workshop
AWS Inferentia Accellertors와 Amazon FSx(고성능 스토리지)와 S3를 활용하여 EKS에서 생성형 AI 챗봇 애플리케이션을 구성해 보자. GenAI with Inferentia & FSx Workshop을 통해 진행한다.

CSI 드라이버 배포
- EKS에서 FSx 고성능 스토리지를 사용할 수 있도록 CSI 드라이버를 배포한다.
# 1단계: account-id 환경 변수 설정
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)
CSI 드라이버의 IAM 정책 및 서비스 계정을 만든다.
# 2단계: CSI 드라이버가 사용자를 대신하여 AWS API 호출을 수행할 수 있도록 하는 IAM 정책 및 서비스 계정을 만듭니다.
# 아래 명령을 복사하여 실행하여 fsx-csi-driver.json 파일을 만듭니다.
cat << EOF > fsx-csi-driver.json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"iam:CreateServiceLinkedRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy"
],
"Resource":"arn:aws:iam::*:role/aws-service-role/s3.data-source.lustre.fsx.amazonaws.com/*"
},
{
"Action":"iam:CreateServiceLinkedRole",
"Effect":"Allow",
"Resource":"*",
"Condition":{
"StringLike":{
"iam:AWSServiceName":[
"fsx.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:ListBucket",
"fsx:CreateFileSystem",
"fsx:DeleteFileSystem",
"fsx:DescribeFileSystems",
"fsx:TagResource"
],
"Resource":[
"*"
]
}
]
}
EOF
# 3단계: IAM 정책 만들기
# 다음 명령을 복사하여 실행하여 IAM 정책을 만듭니다.
aws iam create-policy \
--policy-name Amazon_FSx_Lustre_CSI_Driver \
--policy-document file://fsx-csi-driver.json
IRSA: EKS 생성과 IAM 정책을 맵핑한다.
# 4단계: 드라이버에 대한 Kubernetes 서비스 계정을 만들고 정책을 서비스 계정에 연결합니다.
# 아래 명령을 복사하여 실행하여 서비스 계정을 생성하고 3단계에서 생성한 IAM 정책을 첨부합니다.
eksctl create iamserviceaccount \
--region $AWS_REGION \
--name fsx-csi-controller-sa \
--namespace kube-system \
--cluster $CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::$ACCOUNT_ID:policy/Amazon_FSx_Lustre_CSI_Driver \
--approve
# 5단계: 생성된 역할 ARN을 변수에 저장합니다.
# 아래 명령을 복사하여 실행하여 역할 ARN을 저장합니다.
export ROLE_ARN=$(aws cloudformation describe-stacks --stack-name "eksctl-${CLUSTER_NAME}-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa" --query "Stacks[0].Outputs[0].OutputValue" --region $AWS_REGION --output text)
echo $ROLE_ARN
FSx CSI 드라이버를 배포 및 확인
# 6단계: Lustre용 FSx의 CSI 드라이버 배포
# 다음 명령을 복사하여 실행하여 FSx for Lustre용 CSI 드라이버를 배포합니다.
kubectl apply -k "github.com/kubernetes-sigs/aws-fsx-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.2"
다음 명령을 사용하여 CSI 드라이버가 성공적으로 설치되었는지 확인하세요.
kubectl get pods -n kube-system -l app.kubernetes.io/name=aws-fsx-csi-driver
EKS 클러스터에 영구 볼륨 생성
PV를 생성하기 위해, 이미 프로비정된 FSx의 정보를 가져온다.
FSXL_VOLUME_ID=$(aws fsx describe-file-systems --query 'FileSystems[].FileSystemId' --output text)
DNS_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].DNSName' --output text)
MOUNT_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].LustreConfiguration.MountName' --output text)
FSx의 csi 정보를 올바르게 작성하고, 배포한다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
csi:
driver: fsx.csi.aws.com
volumeHandle: fs-086737f260af6aae6
volumeAttributes:
dnsname: fs-086737f260af6aae6.fsx.us-west-2.amazonaws.com
mountname: rqytbb4v
PVC 생성
fsx-pv의 volumeName 값을 사용하여 미리 프로비저닝 된 PV를 참조한다.
# fsxL-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv
PVC 배포 및 확인
이전 단계에서 정의한 PV와 PVC가 잘 바인딩되는지 확인
# 배포
kubectl apply -f fsxL-claim.yaml
# 확인
kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/fsx-pv 1200Gi RWX Retain Bound default/fsx-lustre-claim <unset> 71s
persistentvolume/pvc-28ef560e-40d6-413c-94fd-9a6b98926532 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 2d4h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/fsx-lustre-claim Bound fsx-pv 1200Gi RWX <unset> 17s
Amazon FSx 콘솔에서 옵션 및 성능 세부 정보 보기
AWS 콘솔에서 다양한 옵션과 모니터링(성능)을 조회할 수 있다.
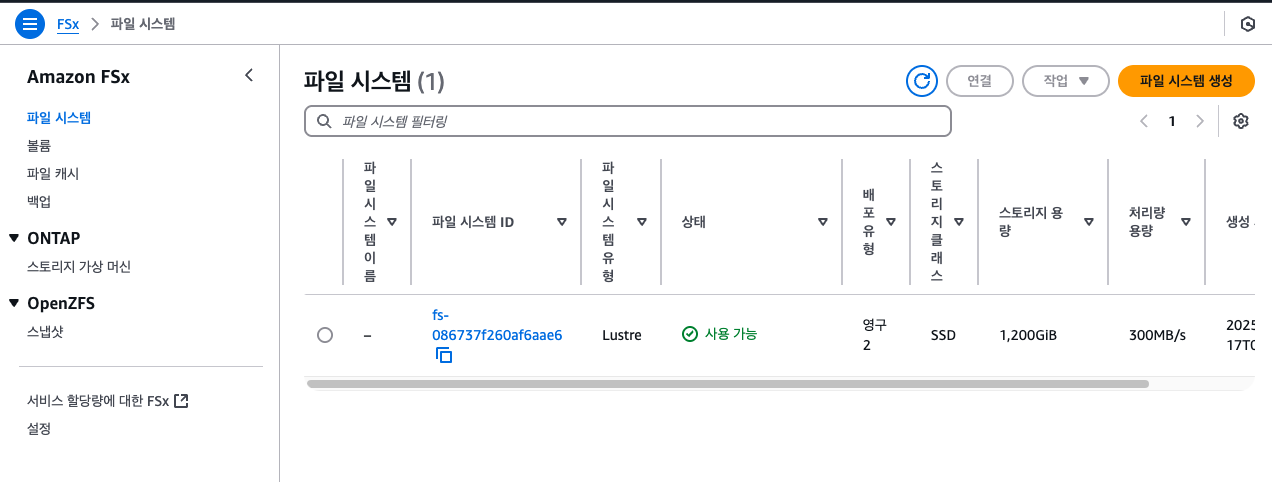

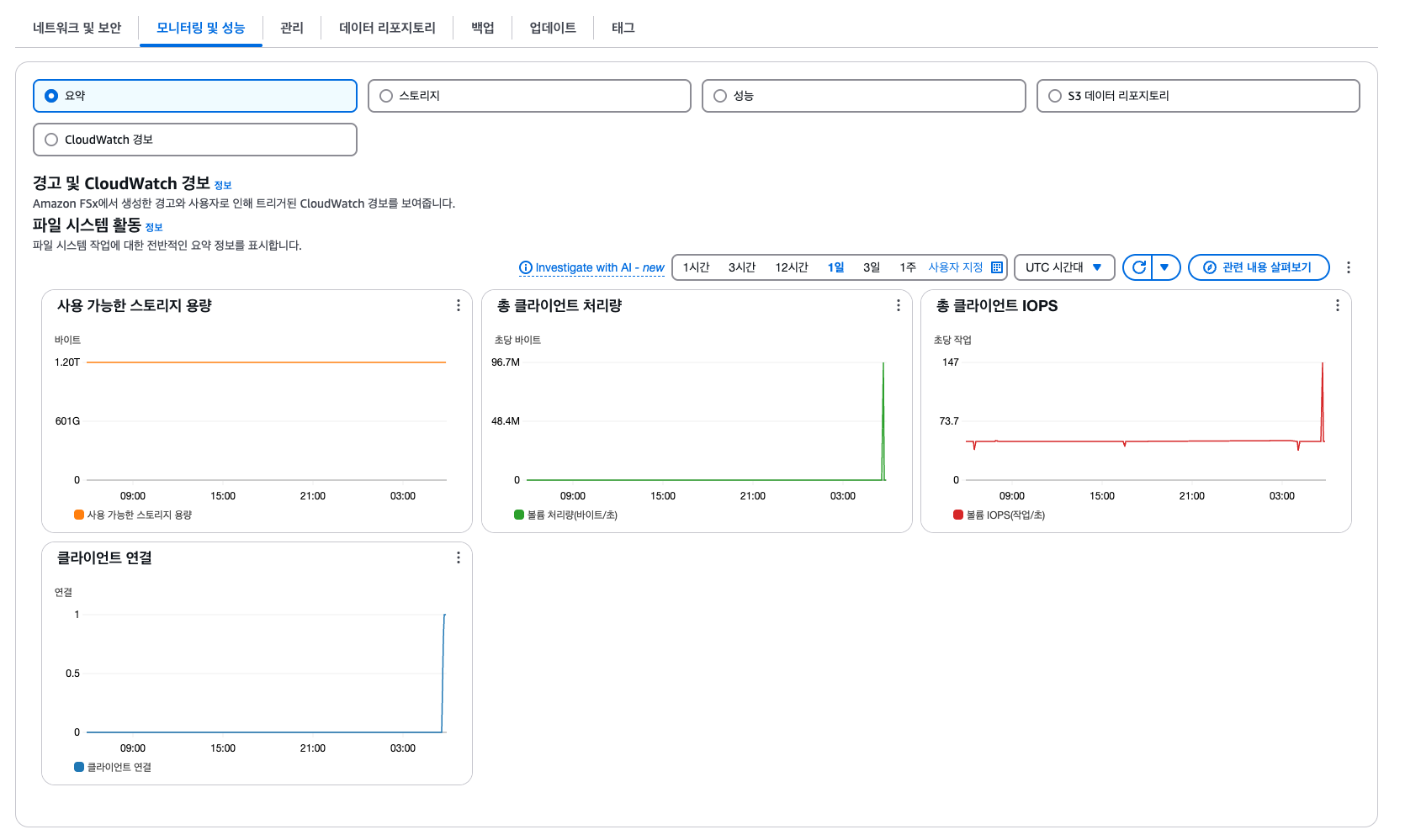

생성형 AI 애플리케이션 배포
AWS Inferentia Accellertors와 Amazon FSx와 S3f를 활용하여, vLLM Pod와 EKS 클러스터에 WebUI Pod를 배포하여, Kubernetes에서 생성형 AI 챗봇 애플리케이션을 구성해 본다.
모델 추론을 위해 AWS Inferentia 노드에 vLLM 배포
Karpenter를 통해 AWS Inferentia INF2 Accelerated Compute 노드에서 실행될 수 있는 Pod 제약 조건을 설정합니다.
# NodePool 확인
cat inferentia_nodepool.yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: inferentia
labels:
intent: genai-apps
NodeGroupType: inf2-neuron-karpenter
spec:
template:
spec:
taints:
- key: aws.amazon.com/neuron
value: "true"
effect: "NoSchedule"
requirements:
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["inf2"]
- key: "karpenter.k8s.aws/instance-size"
operator: In
values: [ "xlarge", "2xlarge", "8xlarge", "24xlarge", "48xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: inferentia
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmpty
# expireAfter: 720h # 30 * 24h = 720h
consolidateAfter: 180s
weight: 100
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: inferentia
spec:
amiFamily: AL2
amiSelectorTerms:
- alias: al2@v20240917
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
volumeSize: 100Gi
volumeType: gp3
role: "Karpenter-eksworkshop"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
tags:
intent: apps
managed-by: karpenter
NodePool 생성
# 배포전 노드 확인
WSParticipantRole:~/environment/eks/genai $ kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-126-73.us-west-2.compute.internal Ready <none> 2d4h v1.30.9-eks-5d632ec
ip-10-0-80-242.us-west-2.compute.internal Ready <none> 2d4h v1.30.9-eks-5d632ec
# NodePool 배포
kubectl apply -f inferentia_nodepool.yaml
Neuron 장치 플러그인 및 스케줄러 설치
EKS 클러스터에 Neuron Device Plugin과 Neuron Scheduler를 설치합니다.
Neuron Device Plugin
Neuron Device Plugin은 Neuron의 디바이스를 Kubernetes에 리소스로 노출합니다.
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin-rbac.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin.yml
Neuron Scheduler
Neuron 스케줄러 확장은 두 개 이상의 Neuron 코어 또는 디바이스 리소스가 필요한 Pod를 스케줄링하는 데 필요합니다.
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-scheduler-eks.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/my-scheduler.yml
vLLM 애플리케이션 파드 배포
모델 제공 기능과 추론 엔드포인트를 제공하는 vLLM 파드를 배포한다.
cat mistral-fsxl.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-mistral-inf2-deployment
spec:
replicas: 1
selector:
matchLabels:
app: vllm-mistral-inf2-server
template:
metadata:
labels:
app: vllm-mistral-inf2-server
spec:
tolerations:
- key: "aws.amazon.com/neuron"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: inference-server
image: public.ecr.aws/u3r1l1j7/eks-genai:neuronrayvllm-100G-root
resources:
requests:
aws.amazon.com/neuron: 1
limits:
aws.amazon.com/neuron: 1
args:
- --model=$(MODEL_ID)
- --enforce-eager
- --gpu-memory-utilization=0.96
- --device=neuron
- --max-num-seqs=4
- --tensor-parallel-size=2
- --max-model-len=10240
- --served-model-name=mistralai/Mistral-7B-Instruct-v0.2-neuron
env:
- name: MODEL_ID
value: /work-dir/Mistral-7B-Instruct-v0.2/
- name: NEURON_COMPILE_CACHE_URL
value: /work-dir/Mistral-7B-Instruct-v0.2/neuron-cache/
- name: PORT
value: "8000"
volumeMounts:
- name: persistent-storage
mountPath: "/work-dir"
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-lustre-claim
---
apiVersion: v1
kind: Service
metadata:
name: vllm-mistral7b-service
spec:
selector:
app: vllm-mistral-inf2-server
ports:
- protocol: TCP
port: 80
targetPort: 8000
LLM 파드가 온라인 상태가 되면 FSx for Lustre 기반 영구 볼륨에서 Mistral-7B 모델(29GB)을 메모리에 로드하여 사용
# 배포: vLLM 배포에는 약 7~8분 소요
kubectl apply -f mistral-fsxl.yaml
Name: vllm-mistral-inf2-deployment-7d886c8cc8-ffdr6
Every 2.0s: kubectl get pod,node ip-172-31-5-77.us-west-2.compute.internal: Sat Apr 19 05:40:50 2025
NAME READY STATUS RESTARTS AGE
pod/kube-ops-view-5d9d967b77-spf9n 1/1 Running 0 2d4h
pod/vllm-mistral-inf2-deployment-7d886c8cc8-ffdr6 0/1 ContainerCreating 0 49s
NAME STATUS ROLES AGE VERSION
node/ip-10-0-126-73.us-west-2.compute.internal Ready <none> 2d4h v1.30.9-eks-5d632ec
node/ip-10-0-80-117.us-west-2.compute.internal Ready <none> 26s v1.30.4-eks-a737599
node/ip-10-0-80-242.us-west-2.compute.internal Ready <none> 2d4h v1.30.9-eks-5d632ec
Open WebUI Chat 사용자 인터페이스를 제공하는 애플리케이션을 배포한다.
cat open-webui.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui-deployment
spec:
replicas: 1
selector:
matchLabels:
app: open-webui-server
template:
metadata:
labels:
app: open-webui-server
spec:
containers:
- name: open-webui
image: kopi/openwebui
env:
- name: WEBUI_AUTH
value: "False"
- name: OPENAI_API_KEY
value: "xxx"
- name: OPENAI_API_BASE_URL
value: "http://vllm-mistral7b-service/v1"
---
apiVersion: v1
kind: Service
metadata:
name: open-webui-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: external
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
spec:
selector:
app: open-webui-server
# type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 8080
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: open-webui-ingress
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/healthcheck-path: /
alb.ingress.kubernetes.io/healthcheck-interval-seconds: '10'
alb.ingress.kubernetes.io/healthcheck-timeout-seconds: '9'
alb.ingress.kubernetes.io/healthy-threshold-count: '2'
alb.ingress.kubernetes.io/unhealthy-threshold-count: '10'
alb.ingress.kubernetes.io/success-codes: '200-302'
alb.ingress.kubernetes.io/load-balancer-name: open-webui-ingress
labels:
app: open-webui-ingress
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: open-webui-service
port:
number: 80
# kubectl apply -f open-webui.yaml
ALB로 구성된 Ingress의 주소로 Open WEB UI를 확인한다.
kubectl get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
open-webui-ingress alb * open-webui-ingress-1012734605.us-west-2.elb.amazonaws.com 80 5s
mistral-7B-Instruct-v0.2 모델 확인

챗봇 기능 확인
한글은 빈약하지만, 기능이 잘 동작함을 확인할 수 있다.

'AWS > EKS' 카테고리의 다른 글
| [AEWS4] EKS가 만들어주는 AWS 리소스 들여다보기 (0) | 2026.03.19 |
|---|---|
| Amazon VPC Lattice로 간소화하는 Amazon EKS 클러스터 통신 (0) | 2025.04.27 |
| AWS EKS 업그레이드, In-place부터 Blue/Green 마이그레이션까지 (1) | 2025.04.02 |
| EKS 서버리스 서비스 간략히 알아보기(Fargate & EKS AutoMode) (0) | 2025.03.23 |
| EKS Karpenter 기본 사용(Node AutoScaling) (1) | 2025.03.05 |